杜文亮深度实践笔记 - chap4 - 缓冲区溢出攻击
4.1 程序的内存布局
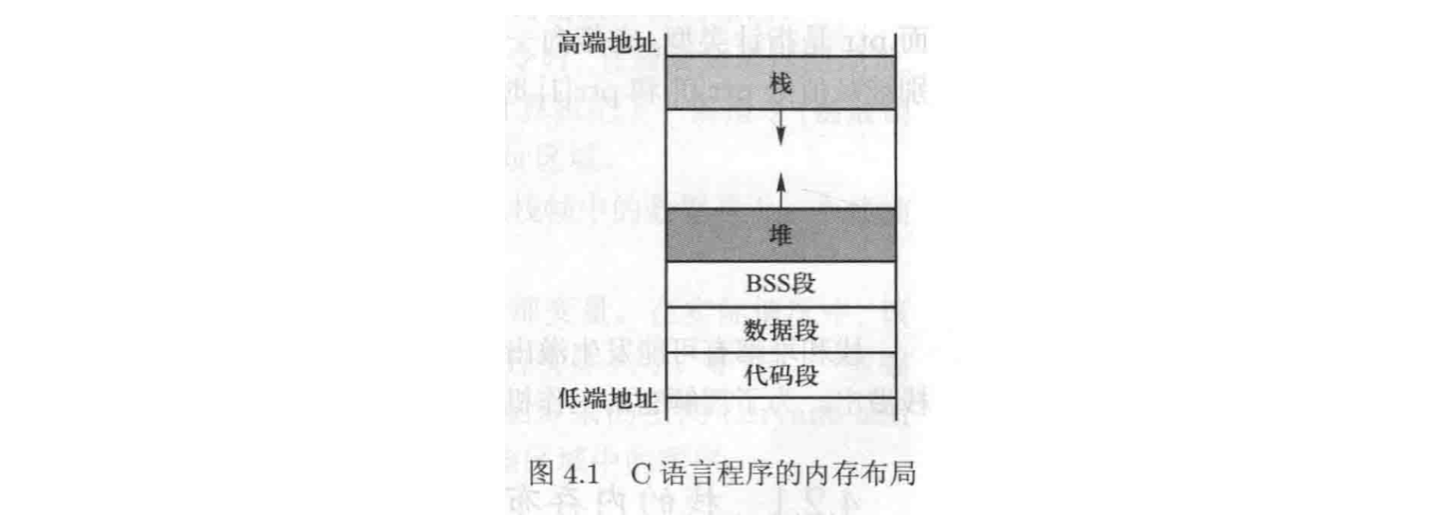
程序运行时需要在内存中存放数据。对于一个 $C$ 语言程序,它的内存由 $5$ 个段组成:
- 代码段(text segment):存放程序的可执行代码,这一内存块通常是只读(Read Only)的。
- 数据段(data segment):存放由程序员初始化的静态(static)/全局(global)变量。
- BSS 段(BSS segment):存放未初始化的静态/全局变量。$OS$ 会把未初始化的变量初始化为 $0$。
- 堆(heap):用于动态内存分配,由
malloc(),free()等函数控制。 - 栈(stack):存放函数内定义的局部变量,以及和函数调用有关的数据。
4.2 栈与函数调用
4.2.1 栈的内存布局
当程序中的函数被调用时,需要在栈中为该函数分配一些空间来存储数据,进而执行该函数。
1 | void calc(int a, int b) { |
当 calc() 被调用时,$OS$ 会在栈顶为该函数分配一块内存空间,称作栈帧(stack frame)。栈帧的布局如下:
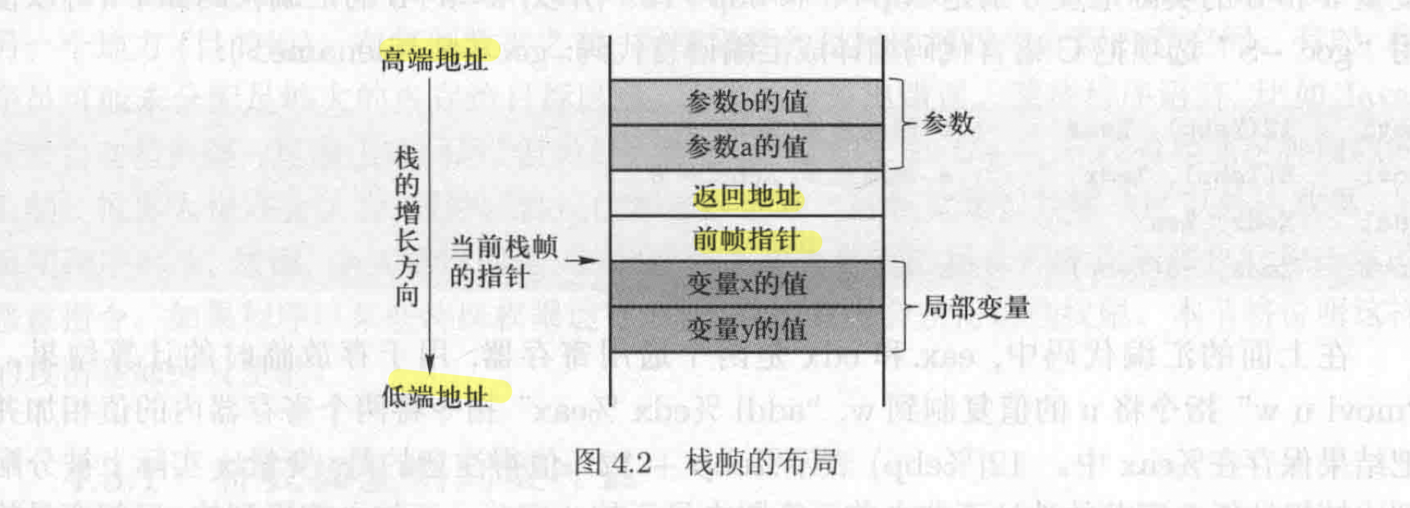
参数:保存给函数传递的参数。顺序是按照相反的顺序存储的。
返回地址:函数结束后需要返回,返回地址区域存储的是函数调用指令的下一条指令的地址。
前帧指针:
局部变量:存放函数中用到的局部变量。
4.2.2 帧指针
在运行函数的时候,肯定会用到函数中的参数和局部变量,所以需要知道他们在内存中的地址。但这些地址在编译的时候是无法确定的,因为编译器无法预测到栈在运行时的状态。所以在 CPU 中引入一个寄存器——帧指针,这个寄存器指向栈帧中的一个固定地址,因此其他参数和局部变量的地址可以通过帧指针加上一个偏移量计算出来。
在 x86 架构中,帧指针寄存器(ebp)总是指向前帧指针的地址。对 32 位体系结构而言,返回地址和帧指针各占 $4$ 个字节,故 $a$ 和 $b$ 的实际地址是 $[ebp] + 8$ 和 $[ebp] + 12$。
之前介绍到的按照相反顺序存储的原因在这里也能得到解释:从偏移度的角度来看顺序不是反的,由于栈是从高端地址向低端地址增长的,若先把参数 $a$ 压入栈中,$a$ 的偏移值将会高于 $b$ 。在阅读汇编代码的时候反而会感到奇怪。


4.3 栈的缓冲区溢出攻击
4.3.1 & 4.3.2 数据复制与缓冲区溢出
1 |
|
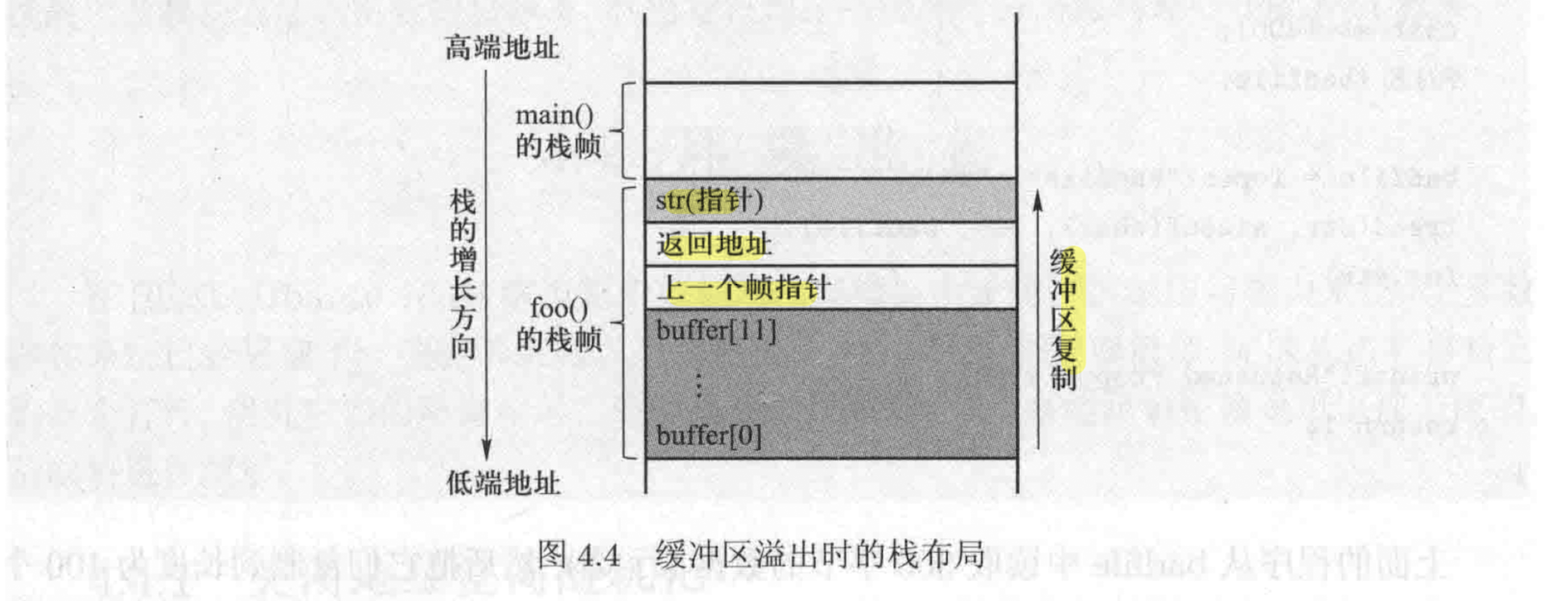
在上面的代码中, foo() 中的局部变量 $buffer$ 拥有 $12$ 字节的内存,foo() 使用 strcpy() 从 $str$ 复制数据到 $buffer$ (直到碰到 \0 才停止执行)。由于 $str$ 的长度比 $12$ 字节大,$str$ 中未被复制完的数据将会被放到 $buffer[12], buffer[13], \cdots$。
若 $buffer$ 之上的区域包含一些关键数据,若他们被修改了,则会引发一些未知的错误。
4.3.3 缓冲区溢出漏洞
1 |
|
上述程序将系统磁盘上的文件读入,该文件是用户可以自定义的,故带来了风险。
杜文亮深度实践笔记 - chap4 - 缓冲区溢出攻击